
Schrottprognose-Modelle in der Radsatzaufbereitung

Maschinelles lernen für die Vorhersage der Ergebnisse von komplexen, wissensintensiven Aufbereitungsprozessen
Radsätze gelten in der Bahnindustrie als eine der wichtigsten Komponenten. Einerseits sind sie sowohl relativ kostenintensiv, als auch hochgradig leistungs- und sicherheitskritisch. Andererseits gehören sie zu den am stärksten beanspruchten Komponenten und erfordern eine umfangreiche Wartung. Folglich ist die effiziente Aufbereitung von Radsätzen sowohl ein anspruchsvoller technischer Prozess als auch ein wichtiger Faktor in der Bahnwirtschaft.
In diesem Projekt, das in Zusammenarbeit mit ÖBB-TS (Technische Dienste der Österreichischen Bundesbahnen) durchgeführt wurde, haben wir Ansätze des maschinellen Lernens entwickelt, um das Ergebnis von Überholungsarbeiten in verschiedenen Phasen des Prozesses vorherzusagen. Dahinter steht das herausfordernde Problem, Radsätze, die wahrscheinlich schwere Schäden erlitten haben, so früh wie möglich zu identifizieren, um unnötige Arbeiten an irreparablen Radsätzen zu vermeiden und die Gesamteffizienz der Anlage zu verbessern.
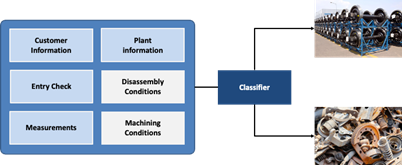
Die ÖBB-TS, unser Hauptpartner in diesem Projekt, betreibt in Knittelfeld konkret eine der größten Radsatzaufbereitungsanlagen Europas und verarbeitet dort jährlich ca. 20.000 Radsätze aus mehreren europäischen Ländern. Jede dieser Einheiten weist individuelle Eigenschaften auf und erfordert unterschiedliche Tätigkeiten, was zu einer hohen Variation im Arbeitsablauf führt. Der daraus resultierende komplexe, wissensintensive Prozess wird mittels 80 verschiedener Aktivitäten an ca. 30 verschiedenen Stationen durchgeführt, die jeweils hochspezialisierte Ausstattung und erhebliches Fachwissen erfordern.
Eine der größten Herausforderungen bei der Anwendung von Techniken des maschinellen Lernens in diesem Kontext ist die Tatsache, dass die meisten der während des Prozesses gesammelten Informationen „weiche“ Indikatoren sind die von Fachkräften gesammelt werden und deren Fachwissen widerspiegeln, die aber auch eine subjektive Komponente enthalten können (im Gegensatz zu „harten“ Werten wie Messungen).
Eine weitere Herausforderung besteht darin, dass die Gründe für schwere Schäden sehr vielfältig sind und dass Verschrottungsentscheidungen von vielen Kontextfaktoren abhängen, einschließlich der Präferenzen des Eigentümers.
Daher verwenden wir eine Vielzahl von Daten, wie z.B. Informationen über die Komponenten und deren Besitzer, Codes, die den Zustand der Teile beschreiben und von den Radsatzbesitzern zur Verfügung gestellt werden, Ergebnisse der visuellen Inspektion vor der Verarbeitung sowie Fehlercodes und Messungen, die während der Aktivitäten an der ersten Station vergeben werden.
Insgesamt resultierte das Projekt in einer Vielzahl von trainierten und optimierten Modellen auf der Basis von Daten über Radsatzaufbereitungsprozesse über vier Jahre und etwa 85.000 Radsätze. Unter Verwendung nur jener Daten, die nach der ersten Inspektion zur Verfügung stehen, konnte das resultierende Modell bereits Vorhersagen machen, die zu signifikanten monatlichen Einsparungen führen. In zukünftigen Arbeiten werden wir gemeinsam mit der ÖBB-TS das Modell ausrollen und weiterentwickeln, um Entscheidungshilfen zu liefern und die Gesamteffizienz zu verbessern.
Vorhersage von Radsatzschrott
Project coordination (Story)
Dr. Elmar Kiesling
Data Integration and Analytics for Digital Production






